
This post marks the beginning of a series exploring how Redmine can be used to implement robust IT Service Management (ITSM) practices. This series will examine various ITSM processes and explore how we can customize Redmine to enhance its efficiency.
Incident Management is one of the key processes within the ITIL methodology. Read the article to find out why you need to manage incidents comprehensively, what the key stages of the process are and how you can use Redmine at each stage. .
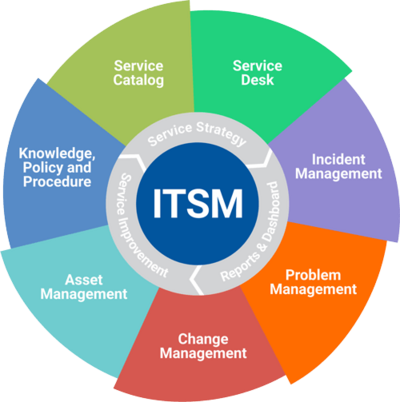
Adopting Redmine for ITSM
Redmine, an open-source project management tool, can be effectively adapted to support a wide range of IT Service Management (ITSM) processes. While primarily known for its project management capabilities, Redmine's flexibility allows it to serve as a robust ITSM solution.
Stay tuned for upcoming posts covering:
- Incident Management: How to efficiently track, prioritise, and resolve incidents.
- Problem Management: Identifying and addressing the root causes of recurring incidents.
- Change Management: Controlling the lifecycle of changes to IT services.
- Release Management: Planning, building, testing, and deploying releases.
- Service Request Management: Handling and fulfilling user requests.
By leveraging Redmine's flexibility and customisation options, organisations can align their IT service delivery with ITIL best practices and improve overall efficiency.
Leveraging Redmine for ITIL Incident Management
In ITIL terminology, an incident is an event that results in an unplanned interruption of service or a reduction in service quality. Incidents include lack of Internet connection, inaccessibility of corporate mail, breakdown of office equipment, and server failures. Such failures are always of an emergency nature and cause serious damage to the business, so the speed of their resolution is important. If the cause of the failure cannot be eliminated immediately, a temporary solution is used. For example, backup server capacity is used.
To minimise the negative impact on business processes and users in such cases, it is necessary to automate the incident management process. To this end, more and more companies in a variety of industries are using service desk systems. They help to reduce the time it takes to resolve faults and malfunctions. The transparency and controllability of the work performed can be increased and documented in detail. The task of distributing incidents to the responsible specialists and teams is simplified. It becomes easier to prioritise and understand which issues need to be addressed first.
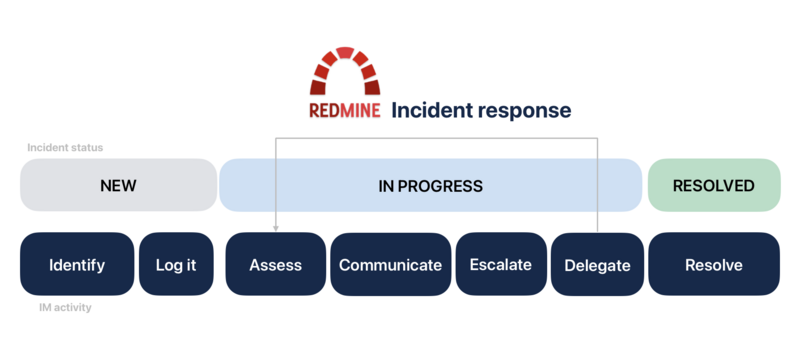
What are the steps involved in incident management?:
The ITIL incident management process includes several stages. Let's consider how the capabilities of the service automation system help to manage detected failures at these stages.
Detection
The failure can be detected both by users who encountered unavailability of the service and by a specialised monitoring system. In the first case, the user should send a request to eliminate the incident, which will be distributed to the responsible specialist.
In the second case, it is optimal if the monitoring system is integrated with the Helpdesk. Then the latter will automatically generate a request to solve the fixed problem. Sometimes this allows support specialists to neutralise a failure before the company's employees or customers even know about it.
Logging
The detected incident is logged and described to provide support professionals with a baseline of the problem. The accuracy of the information often determines how quickly the situation can be corrected. Whether the specialist will have to spend additional time to clarify the nuances or whether everything will be immediately clear from the problem description.
The service desk system also helps to correctly register an incident. When creating a request, the user fills out a form that contains the necessary fields. The time of the failure, what exactly happened, the user's contact information and details - all the information is collected in one request. It can be registered in the system in different ways. For example, submit a request via the self-service portal, email, or mobile application.
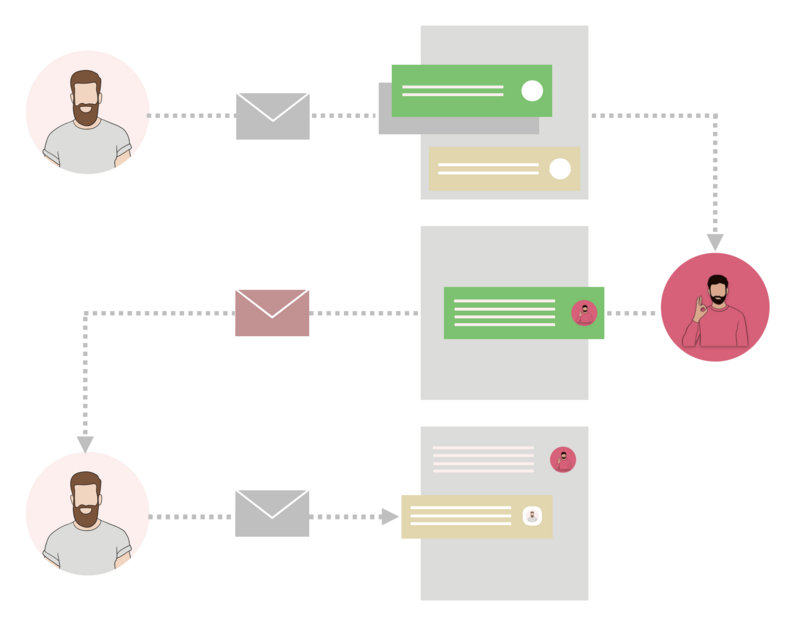
Create requests using email
Some customers might prefer to email the service desk to open a request. Project admins can set up email requests under project settings. All communication history between agents and customers is automatically saved as incident comments.
Here’s how sending requests by email works:
- A customer sends a request to the service project email address. The request becomes a ticket in the Service Project and is added to a queue.
- An agent responds to the ticket.
- The customer receives an email notification containing the agent's comment.
- The customer replies to the email notification, and the reply appears as a comment on the ticket in the Service Desk project.
Categorisation
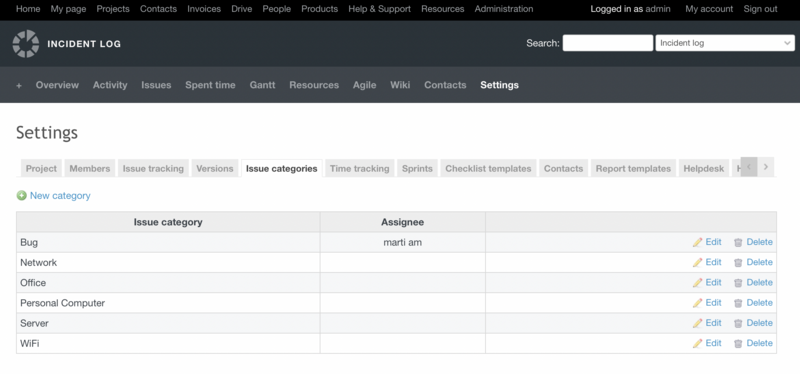
This is sorting incidents into different categories. For example, they may depend on the specific IT services affected by the failure. Often, the category chosen affects which specialists or teams will deal with the problem and how quickly it needs to be fixed.
In addition to assigning responsibilities and deadlines, categorisation helps you analyse trends in similar incidents and keep statistics on them. The most convenient way to perform such tasks is through the service desk, where automatic categorisation can be set up.
Prioritisation
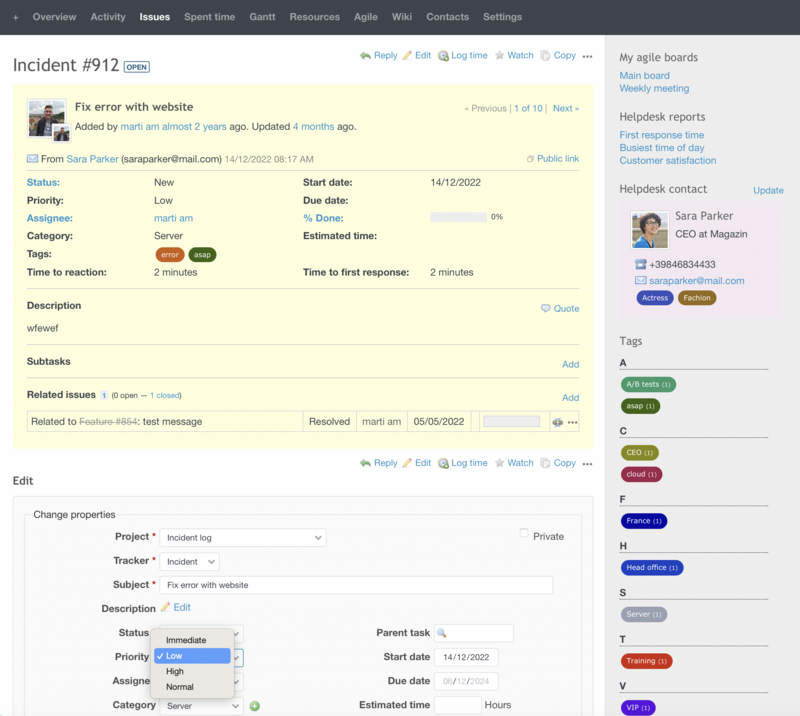
The urgency of failure resolution is determined, which is regulated in SLA indicators. In order not to define this parameter manually every time, it is better to set up prioritisation in the service desk. For example, by default, the system will assign a priority based on the type of affected configuration unit, the failed service and its criticality for business processes, and the degree of service disruption.
Diagnosis
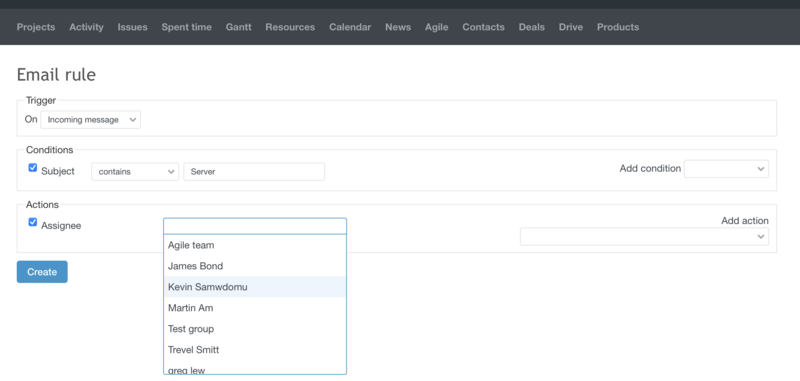
This is where the direct implementers who are supposed to fix the incident come into the process. In the course of diagnostics, they determine the causes and extent of the failure. The service desk functionality of the system will also be useful for this purpose. In it, you can maintain a knowledge base in which to accumulate information about already completed requests for the elimination of incidents. When similar problems occur, such materials help to understand the causes faster.
Migrate to secure hosting
Don't waste your time on Redmine maintenance. Hire experts and focus on your projects
Configuration management databases (CMDBs) also simplify the diagnostic task. These databases show how infrastructure elements are interconnected. For example, when a user requests a PC repair, the support specialist immediately sees the software installed in the equipment. It becomes clearer that some programs conflict with each other, or the PC is involved in processes that require higher technical characteristics. Based on this information, the nature of the problem is quickly identified, which makes it possible to take the necessary measures to eliminate it.
Use an automation rule to auto-assign new tickets to the right team or agent based on factors like issue type and priority.
Escalation
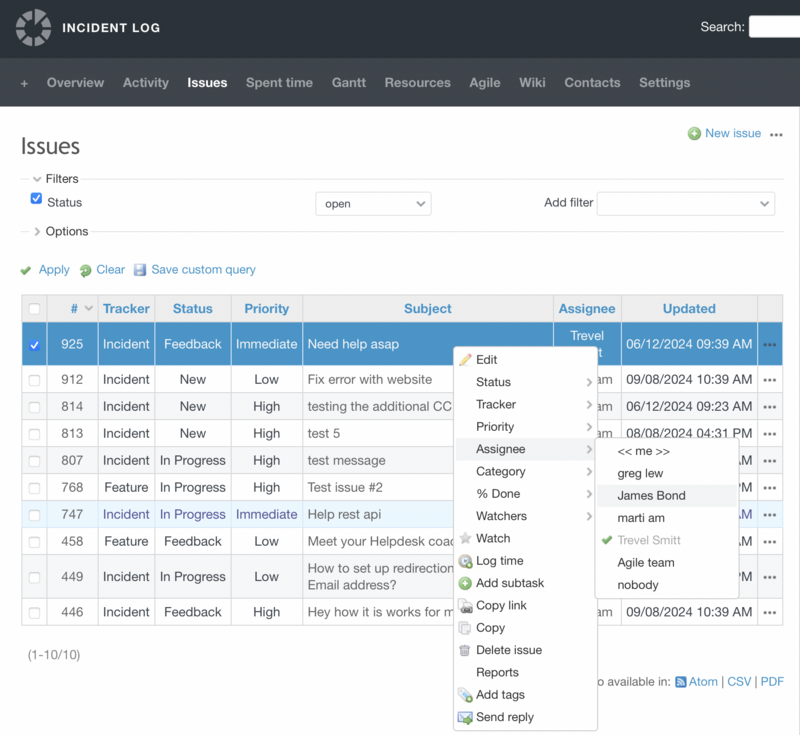
This stage is relevant when the issue is stalled for some reason and the assistance of more highly qualified specialists or the service desk management is required. In such cases, the service desk is configured to redirect the request from the first to the second or third support line. Another possible scenario is automatic notification of the service manager or service supervisor that there is a certain amount of time left until the deadline for fulfilment of the request.
Solution
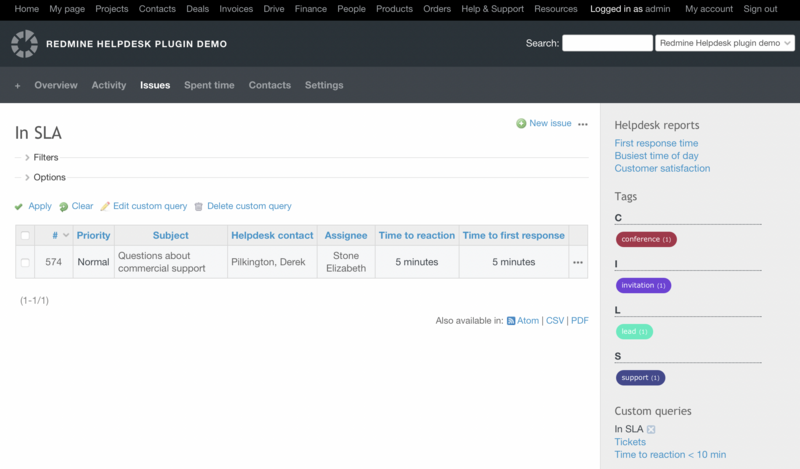
Once the causes of the incident are clarified, work begins to restore the service. Support specialists can meet the deadlines set by the IT system to control the reaction time and problem elimination in accordance with SLA. Due to the incident history, it is possible to study how similar issues have already been solved. All information about the current incident and actions taken to restore the service will also be automatically saved in the system for further analysis by specialists.
Closure
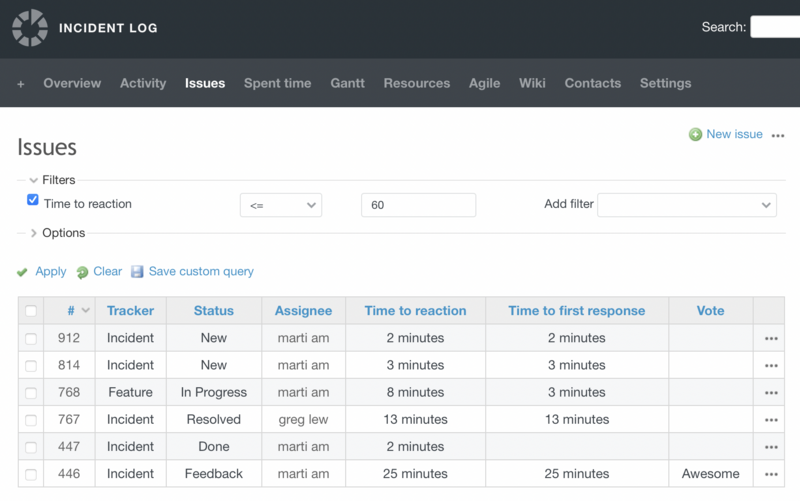
This is the final stage of incident management. The support specialist closes the request, and the user who sent it confirms the resolution of the issue. When closing an incident, the service desk records the time and date of its elimination, the list of completed works, and other important information. In turn, the user can evaluate the quality of work performed.
Incidents are critical failures of infrastructure and services. Since service unavailability negatively affects business processes, the main priority is the speed of incident resolution.
ITIL methodology regulates that incident management includes several main stages. At each of them, it is easier to cope with the tasks arising before the support service with the help of the service desk system capabilities, which allows to automate the process.
Agile Transformation of the Service Desk
Agile and Lean related tools and techniques can also be helpful to incident management teams, for example, by 1) using Kanban boards to make the overall work and prioritisation visible and 2) limiting the amount of work in progress (WIP) to ensure that we're not trying to tackle too many things at once, which can reduce our overall flow and the speed at which we can get things done.
AI for incident management
The AI bot can provide human agents with detailed insights and relevant information by analysing previous cases of similar issues and suggesting possible solutions. This speeds up resolution and improves the quality of support provided to the user.
Finally, the bot can also summarise call transcripts or text-based conversations into concise notes, significantly reducing the time agents spend on this task. The AI can highlight key issues discussed, steps taken, and solutions provided, making the documentation process more efficient and accurate.
Migrate to secure hosting
Don't waste your time on Redmine maintenance. Hire experts and focus on your projects
Conclusion
By effectively leveraging Redmine's features and customising workflows, you can align your incident management practices with ITIL principles and improve your organisation's overall IT service delivery. In the next part of this series, we will delve deeper into specific Redmine configurations and best practices for ITSM.
